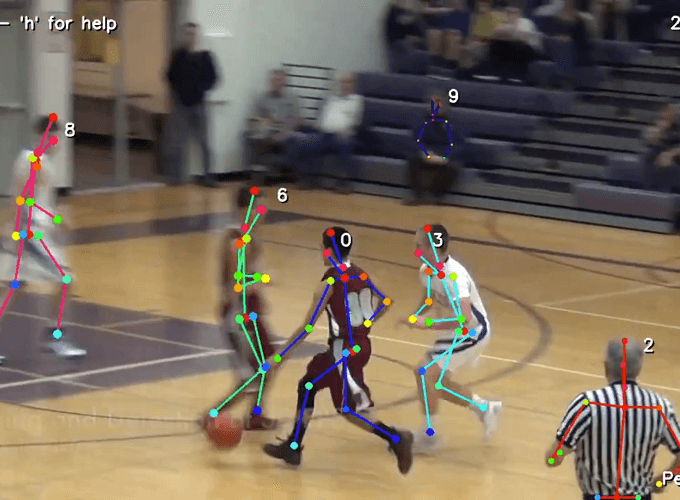

Real-time detect and track 2D poses of multiple people at 30 fps on a single GPU. Source
In this post, we will review a new paper named “Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields” from CVPR 2019.
The authors present an online approach to efficiently and simultaneously detect and track 2D poses of multiple people at 30 fps on a single GPU.
According to the author, this is “current the fastest and the most accurate bottom-up approach that is runtime-invariant to the number of people in the scene and accuracy-invariant to input frame rate of camera.”
Some highlights of the paper:
- Robust and invariant to input frame-rate, even at 6Hz input
- Handles fast moving targets and camera movements
- Run-time invariant to numbers of people in the frame.
- Propose Spatio-Temporal Affinity Fields (STAF) which encode connections between keypoints across frames.
- Propose a novel temporal topology cross-linked across limbs which can handle moving targets, camera motion and motion blurs.
Here are the results of the authors.
Outline
- Introduction
- Overall pipeline
- Cross-Linked Topology
- Results
- Limitation
- Implementation
- References
- My Reviews
Introduction
Human pose and tracking have received remarkable attention in the past few years. The recently introduced PoseTrack dataset is a large scale corpus of video data that enable the development of this problem in the computer vision community.
There are several other works on this problem. However, none of those methods are able to run in real-time as they are usually:
- Follow the top-down methods of the detection and tracking tasks which required more computation as the number of people increased.
- Require offline computations or stack of frames which reduces the speed and did not achieve better results for tracking than the Hungarian algorithm baseline.
In this paper, the authors aim to build a truly online and real-time multi-person 2D pose estimator and tracker. The author work on videos in a recurrent manner to make the approach real-time. They leverage information from the previous frame by combining 1) keypoint heatmaps 2) Part Affinity Fields and 3) Spatio-Temporal Affinity Fields (STAF).
The authors extend the Part Affinity Fields in OpenPose from the CVPR 2017. The authors of this paper are also the author of OpenPose. Feel free to check our previous blog post on OpenPose.
Overall pipeline
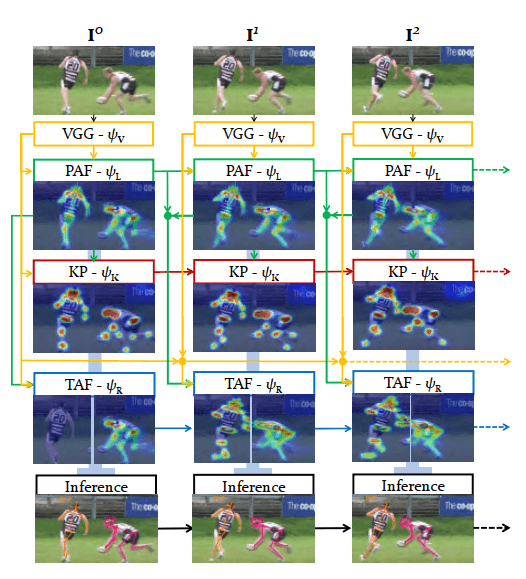
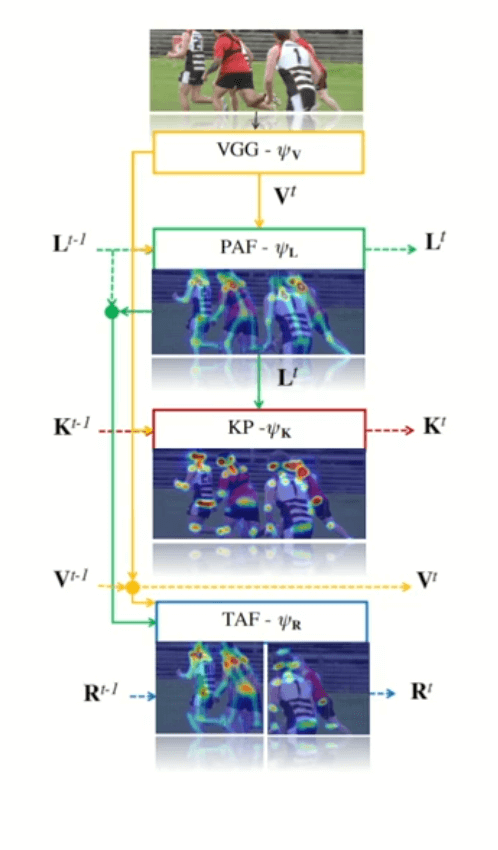
The Overall pipeline of the STAF algorithm. Source
The above figure is the overall pipeline of the Spatio-Temporal Affinity Fields (STAF) algorithm. The video frames are processed in a recurrent manner across time including:
- Extract VGG features.
- Extract Part Affinity Fields (PAFs)
- Extract KeyPoints Heatmaps
- Extract connections between keypoints across frames as Temporal Affinity Fields (TAFs).
VGG features

VGG features. Source
For frame $I^t$ at time t of the video, they computed as: $$V^t = \psi_V(I^t)$$
PAFs and Keypoints Heatmaps
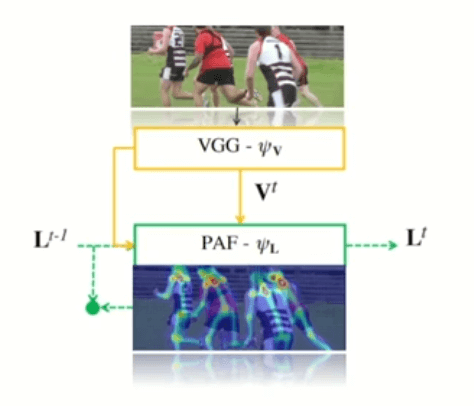
Part Affinity Fields (PAFs). Source
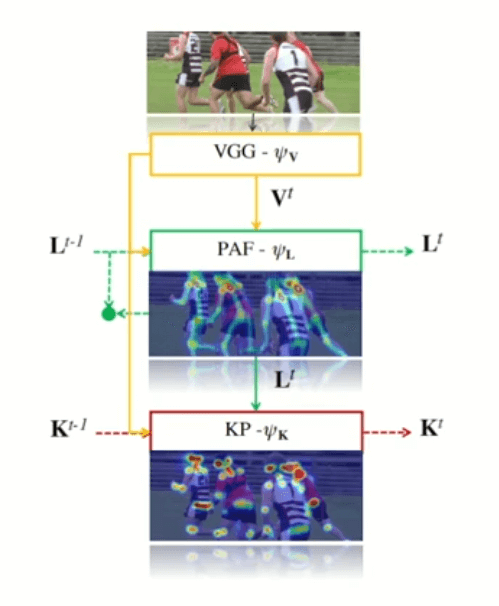
Keypoints Heatmaps. Source
The PAFs and Keypoints heatmaps are very similar to the OpenPose approach, except that they will also use the information from the previous frame.
In the paper, there are three methods to compute the PAFs:
- Use 5 previous frame data.
- Only use 1 previous frame.
- Estimate PAFs and TAFs at the same time.
In their experiments, they found that:
- Method 1 produces good results but is the slowest due to recursive stages.
- Method 2 boosts up the speed without major loss in performance.
- Method 3 is the most difficult to train but has the fastest speed.
We only discuss the Method 2 in this blog. For other methods, please check the original paper.
Method 2 computes the PAFs and keypoints in a single pass as follows: $$L^t = \psi_L(V^t, L^{t-1})$$ $$K^t = \psi_K(V^t, L^t, K^{t-1})$$
Temporal Affinity Fields (TAFs)
Temporal Affinity Fields (TAFs) encode connections between keypoints across frames.
These TAFs are vector fields which indicate the direction in which each body joint is going to move from frame $I^{t-1}$ to frame $I^t$. TAFs are also introduced in the paper by Andreas Doering et.al.
In the following image, TAFs are represented as the blue arrow $R^t$.
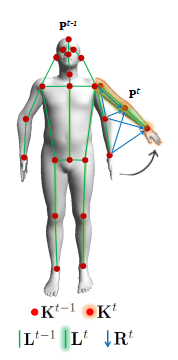
Connections between keypoints across frames. Source
Temporal Affinity Fields (TAFs). Source
Inference
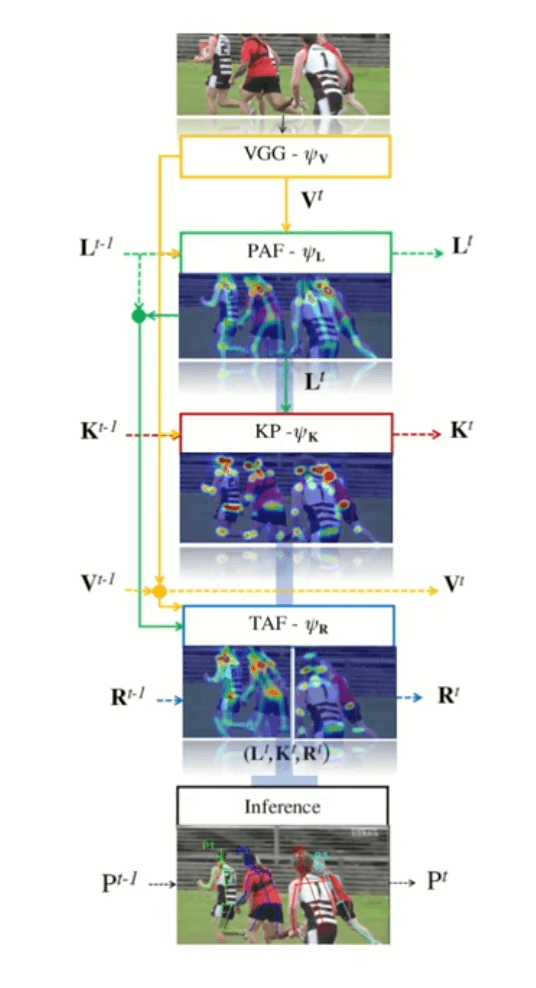
Inference. Source
Both the inferred PAFs and TAFs are sorted by their scores before inferring the complete poses and associating them across frames with unique ids.
Here are the steps: Going through each PAF in the sorted list:
- Initialize a new pose if both keypoints in PAF are unassigned
- 01 keypoint is assigned: add to existing pose
- Both keypoints are assigned: update score of PAF in pose to the same pose.
- Both Keypoints are assigned to different poses: Merge two poses
- Assign id to each pose in the current frame with the most frequent id of keypoints from the previous frame.
Here is the detailed algorithm from the original paper:

Algorithm: Estimation and tracking of keypoints and STAFs. Source
Cross-Linked Topology
There are three possible topology variants for STAFs.
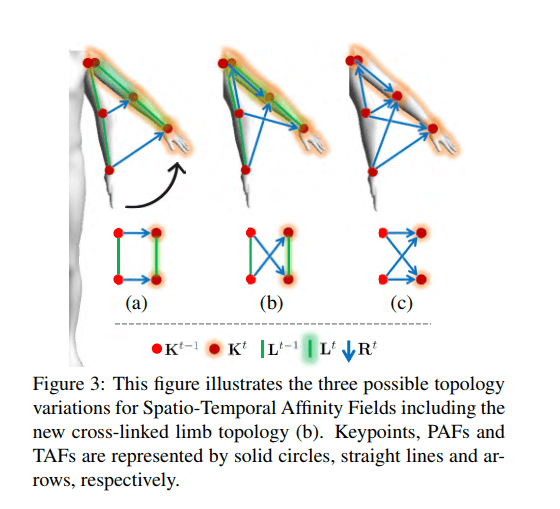
Topology variants for STAFs. Source
The Topology A is the Keypoint TAF and lacks associative properties when a keypoint has minimal motion or when a new person appears.
The Topology B and Topology C are cross-linked limb topologies. The author shows that cross-linked limb topologies can solved the motion problem from Topology A. When there is minimal motion, the TAFs are simply become the PAFs at that limb.
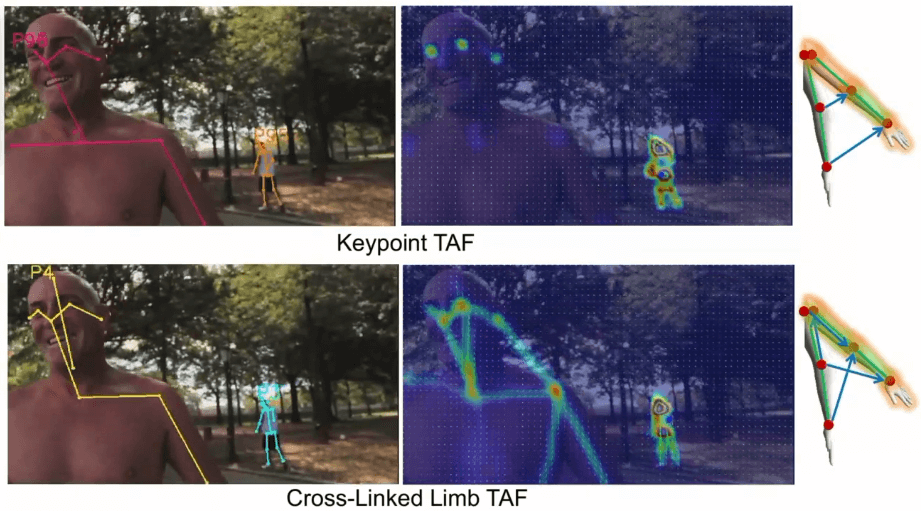
Keypoint TAF vs Cross-Linked Limb TAF. Source
In the paper experiments, the Topology C is under-performed compared to Topology B.
Results
- The method can achieve high accuracy even when the framerate drops to 6Hz.
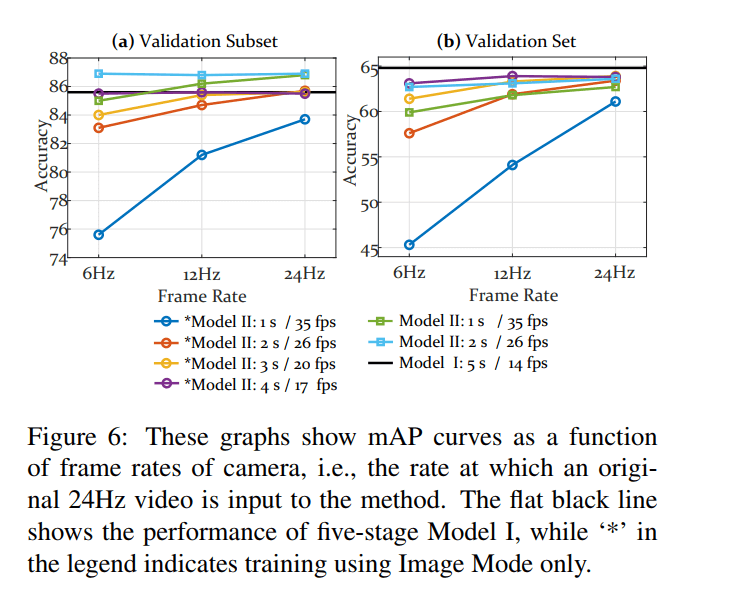
Camera framerate experiments of STAFs. Source
- The method can achieve high accuracy and fast inference speed.
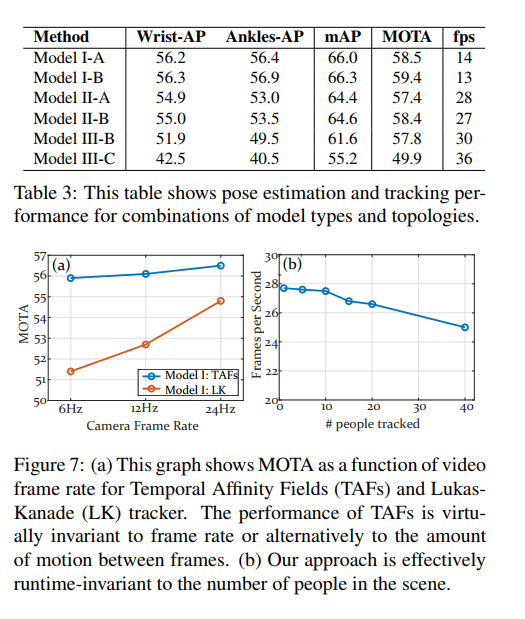
Camera framerate experiments of STAFs. Source
- The method can achieve competitive results on the PoseTrack Dataset.
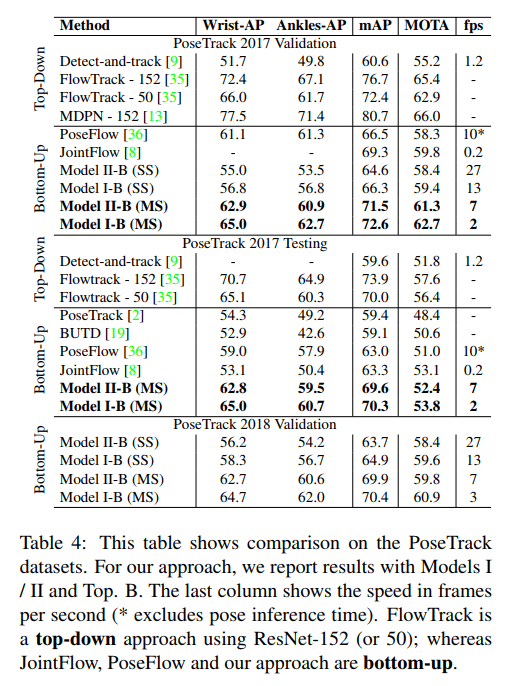
Camera framerate experiments of STAFs. Source
Limitations
There are some limitations in this work:
- This paper haven’t embedded a re-identification module to handle cases of people leaving and re-apprearing the scene.
- This method is unable to handle scene changes. Therefore, one may need to detect the scene changes and restart the process from that frame.
Implementation
This paper is open-sourced at the author repository: soulslicer/openpose.
This is a fork from OpenPose repository. In the near future, they will be merged and you can use it directly from OpenPose.
References
- [1] Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, Yaser Sheikh, Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields, CVPR 2019
- [2] Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh, Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (2017), CVPR 2017
- [3] Andreas Doering, Umar Iqbal, Juergen Gall, Joint Flow: Temporal Flow Fields for Multi Person Tracking, CoRR, abs/1805.04596, 2018
- Project page: Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
- Github Code: soulslicer/openpose
My Reviews
- Image Classification: [NIPS 2012] AlexNet
- Image Segmentation: [CVPR 2019] Pose2Seg
- Pose Estimation: [CVPR 2017] OpenPose
- Pose Tracking: [CVPR 2019] STAF