
In this post, we will review the paper “Pose2Seg: Detection Free Human Instance Segmentation” from CVPR 2019. The paper presents a new approach to human instance segmentation which separates instances based on human pose, rather than proposal region detection.
Some highlights of this paper:
- Pose-based framework for human instance segmentation which can achieve better accuracy and can better handle occlusion than SOTA detection based approach.
- A new benchmark “Occluded Human (OCHuman)” which focuses on occluded humans with annotations including bounding-box, human pose and instance masks.
Outline
Introduction
Human pose estimation and segmentation are important information to have better understanding about human activity. There are lots of research focused on this topic. One of the most popular deep learning methods is Mask R-CNN which is a simple and general framework for object instance segmentation.
Even through methods like Mask-RCNN can detect objects and generate segmentation mask for each instance in the image. There are some problems with these approaches:
- These methods perform the object detection first, then remove the redundant regions using Non-maximum Suppression (NMS) and segment the object from the detection bounding-box. When two objects of the same category have a large overlap, NSM will treat one of them as a redundant proposal region and eliminates it.
- “Human” is a special category and can be defined based on the pose skeleton. The current methods like Mask-RCNN don’t take advantage of the pose information for segmentation.
The proposed method in this paper, Pose2Seg, is designed specifically for human instance segmentation with the following advantages:
- Use bottom-up approaches which is based on the pose information rather than the bounding box detection.
- Designed to solve the occlusion problem where each human instance is heavily occluded by one or several others.
Occluded Human Benchmark (OCHuman)
Occluded Human Benchmark (OCHuman) dataset is introduced in this paper to emphasize occlusion as a challenging problem for researches to study and encourage the algorithms to become more practical for real life situations.
Occluded Human Benchmark (OCHuman) dataset contains 8110 detailed annotated human instances with 4731 images. On average, over 67% of the bounding-box area of a human is occluded by one or several other persons.
Here are some images from the OCHuman dataset:

OCHuman dataset
Here is a table which compares COCO Dataset and OCHuman Dataset.
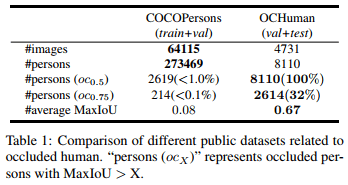
As you can see, COCO contains few occluded human cases and it can not help to evaluate the capability of methods when faces with occlusions.
OCHuman is designed for all three most important tasks related to humans: detection, pose estimation and instance segmentation.
The most important aspect of OCHuman is the average MaxIoU which is 0.67. That means over 67% of the bounding-box area of a human is occluded by one or several other persons. This is a very common problem in real life applications such as video surveillance or in-store human behaviour analysis.
Architecture
The structure of Pose2Seg is shown in the following image:
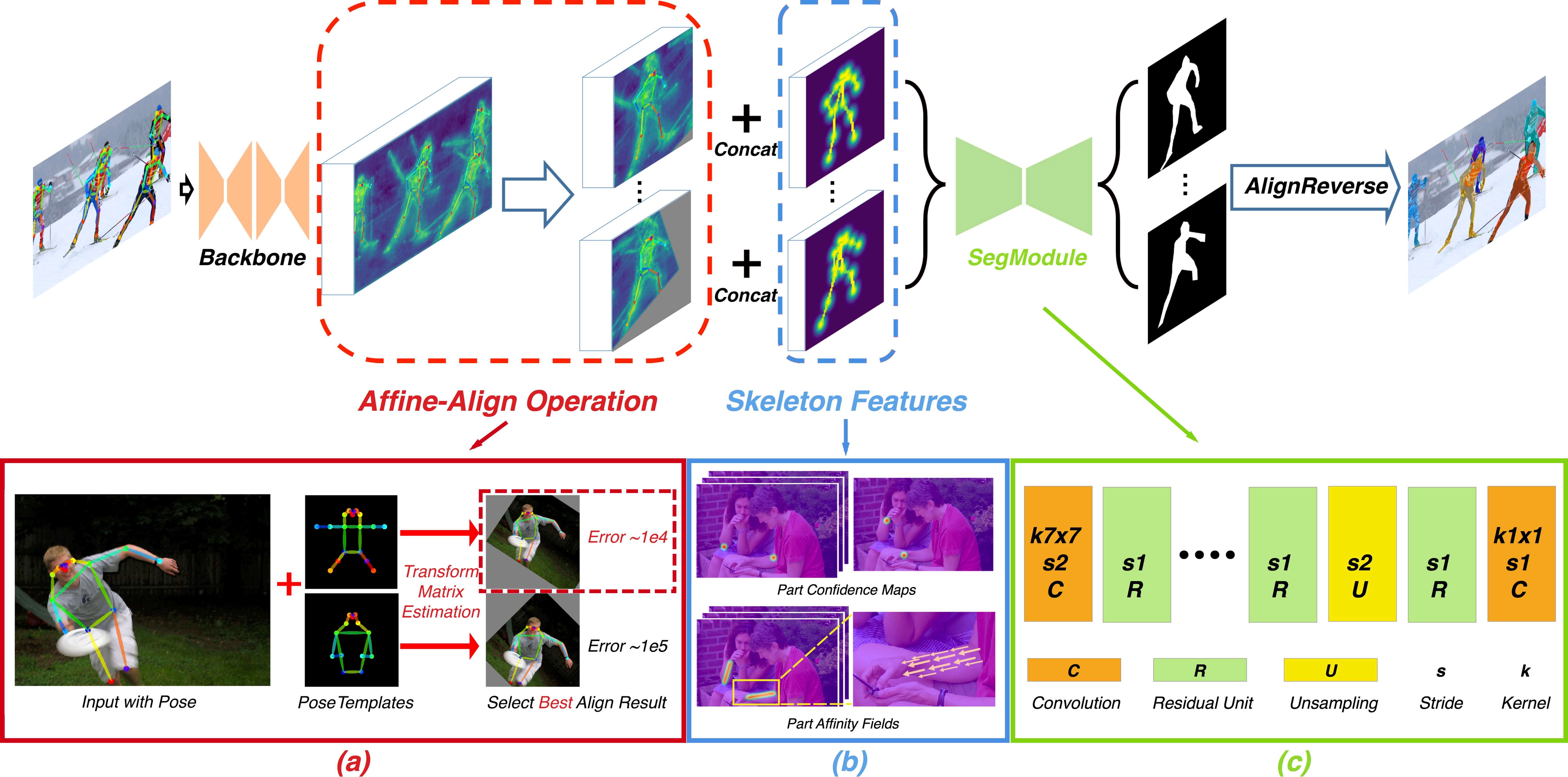
The steps of this method can be described as follows:
- First, the model takes both the image and human pose as input. The human pose can be the output of other methods such as OpenPose or the ground truth of the dataset. We have a blog review about the OpenPose method.
- The entire image is passed through a base network to extract features of the image.
- An align module, Affine-Align, is used to align Regions of Interest to a uniform size. You can imagine that this module will extract multiple fixed-size regions from the large image. Each fixed-size region is correspond for each human in the image. Then, the Affine-Align region will perform affine transformations to align each pose to one of the pose templates.
- The aligned output of the Affine-Align will be concatinated with Skeleton Features and feed toward a SegModule to generate the segmentation mask.
- Skeleton features: are simply the part affinity fields (PAFs) which is a 2-channel vector field map for each skeleton. This is the output of the OpenPose.
- SegModule: is a CNN network which starts with 7 x 7 stride-2 conv layer and is followed by several standard residual units. Then, a bilinear upsampling layer is used to recover the resolution and 1 x 1 conv layer are used to predict the mask result.
- Finally, the segmentation masks for each person is combined into one final segmentation mask using the reverse of the affine transformation from Affine-Align.
Experiments
Performance on occlusion
Pose2Seg can achieve nearly 50% higher than the Mask R-CNN on OCHuman dataset. The author also tests using the ground-truth keypoints as input and more than double the accuracy (GT Kpt).

Some results on occlusion cases:

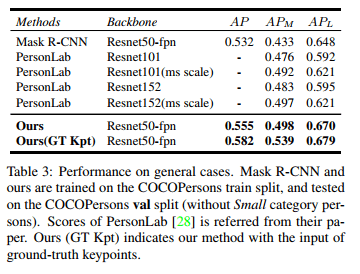
Performance on general cases
- Pose2Seg can also achieve higher accuracy than other approachs on COCOPersons dataset.
Implementation
The official PyTorch code for the paper can be found at https://github.com/liruilong940607/Pose2Seg
References
- [CVPR 2019] Pose2Seg: Detection Free Human Instance Segmentation
- OCHuman(Occluded Human) Dataset
- [CVPR 2017] OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
My Reviews
- Image Classification: [NIPS 2012] AlexNet
- Image Segmentation: [CVPR 2019] Pose2Seg
- Pose Estimation: [CVPR 2017] OpenPose
- Pose Tracking: [CVPR 2019] STAF