
Nội dung bài viết
Giới thiệu
Trong bài viết này, mình sẽ hướng dẫn các bạn xây dựng mô hình nhận diện chữ viết trên tập dữ liệu MNIST bằng cách sử dụng PyTorch.
Tập dữ liệu MNIST
MNIST được giới thiệu năm 1998 bởi Yann Lecun và cộng sự nhằm đánh giá các mô hình phân lớp. MNIST là tập dữ liệu chữ viết từ 0 đến 9.
Trong đó, mỗi hình là một ảnh đen trắng chứa một số được viết tay có kích thước là 28x28. Bộ dataset vô cùng đồ sộ với khoảng 60k data training và 10k data test và được sử dụng phổ biến trong các thuật toán nhận dạng ảnh.
Website chính thức của tập dữ liệu: http://yann.lecun.com/exdb/mnist/.
Source code
Toàn bộ mã nguồn sử dụng trong bài viết được cung cấp tại link sau: quanhua92/deeplearning.vn
Xây dựng mô hình bằng PyTorch
Cấu trúc project
Trong project này, mình sẽ dùng 2 file là main.py và models.py. Trong đó, main.py sẽ chứa các đoạn code để thực hiện quá trình training và models.py sẽ chứa mô hình network được dùng trong main.py.
.
├── main.py
└── models.py
Import thư viện và một số tham số
Đầu tiên, chúng ta cần import một số thư viện sẽ sử dụng trong file main.py.
# main.py
import torch
import matplotlib.pyplot as plt
import numpy as np
import torchvision
from torch import nn, optim
from torchvision import datasets, transforms
Ngoài ra, chúng ta sẽ định nghĩa một số tham số sẽ dùng trong phần sau bao gồm:
batch_size: Lượng ảnh sẽ dùng trong 1 batch.learning_rate: Learning Rate sẽ dùng vớioptimizer.num_epochs: Số lần sử dụng toàn bộ dữ liệu để train.
batch_size = 32
learning_rate = 0.01
num_epochs = 20
Data Loader
Tiếp theo, chúng ta sẽ sử dụng package datasets.MNIST có sẵn trong torchvision để tự động tải về bộ dữ liệu vào thư mục data và áp dụng một số transforms. Dữ liệu MNIST sẽ có miền giá trị [0, 1]. Do đó, để chuẩn hóa dữ liệu về mean bằng 0 và std bằng 1, ta cần sử dụng hàm Normalize với mean của toàn dữ liệu bằng 0.1307 và std bằng 0.3081.
# Data Loader
train_loader = torch.utils.data.DataLoader(
datasets.MNIST("data", train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, )),
])),
batch_size=batch_size,
shuffle=True)
val_loader = torch.utils.data.DataLoader(
datasets.MNIST("data", train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, )),
])),
batch_size=batch_size,
shuffle=False)
Chúng ta sẽ thử hiển thị một số hình có trong bộ dữ liệu bằng đoạn code sau:
# Visualize Data
def imshow(img, mean, std):
img = img / std + mean # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images), 0.1307, 0.3081)
print(labels)
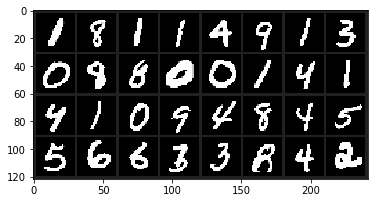
Bạn sẽ có được một hình tương tự như sau:
Ngoài ra, trong console, bạn sẽ thấy nhãn của từng hình như sau:
tensor([1, 8, 1, 1, 4, 9, 1, 3, 0, 8, 8, 0, 0, 1, 4, 1, 4, 1, 0, 9, 4, 8, 4, 5,
5, 6, 6, 3, 3, 8, 4, 2])
Bên cạnh đó, nếu bạn thử gọi images.shape và labels.shape. Bạn sẽ có kết quả như sau:
images.shape: torch.Size([32, 1, 28, 28]). Trong đó, 32 là batch size, 1 là số channel, 28 là chiều cao ảnh và 28 cuối là chiều rộng của ảnh. Do format mặc định của PyTorch là NCHW.labels.shape: torch.Size([32]). Ở đây, chúng ta có 32 nhãn tương ứng với batch size là 32.
Model
Như vậy, chúng ta đã có thể load được dữ liệu để train và validation. Tiếp theo, chúng ta sẽ xây dựng một mạng Convolution Neural Network (CNN) đơn giản với 1 layer conv và 1 layer fully connected. Đoạn code sau sẽ ở trong file models.py:
# models.py
from torch import nn
class SimpleModel(nn.Module):
def __init__(self, num_classes=10):
super(SimpleModel, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=5, padding=2, stride=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(14 * 14 * 32, num_classes)
def forward(self, x):
out = self.conv1(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
Ở đây, mình tạo một class SimpleModel kế thừa từ nn.Module. Đây sẽ là mô hình mạng chúng ta sẽ dụng trong file main.py.
Mình tạo 1 lớp là self.conv bao gồm các bước là nn.Conv2d -> nn.Relu() -> nn.MaxPool2d.
nn.Conv2d: có input là 1 channel và output là 32 channels. Ngoài ra, kernel_size là 5 với padding bằng 2 và stride 1. Do đó, output của lớpnn.Conv2dnày sẽ là một feature map có kích thước là[N, 32, 28, 28].nn.Relu: là activation function RELUnn.MaxPool2d: là max pooling layer. Trong đó ta dùng kernel_size bằng 2 và stride bằng 2. Do đó, output của lớp này là feature map có kích thước là[N, 32, 14, 14].
Ngoài ra, mình còn tạo ra một lớp fully connected là self.fc với input là 14 * 14 * 32 khớp với output của lớp self.conv1 và output là số lượng class bằng 10.
Trong hàm forward với input x là một batch có kích thước [N, 32, 28, 28]. Đầu tiên, mình cho x qua lớp self.conv1. Sau đó, mình dùng hàm view để chuyển biến out từ một tensor 4 chiều [N, 32, 14, 14] thành một tensor 2 chiều là [N, 32 * 14 * 14]. Trong đó, out.size(0) chính là batch_size ban đầu bằng 32.
Quay lại file main.py, chúng ta sẽ dùng GPU nếu có thể. Do đó, mình tạo một biến device để có thể dùng GPU hoặc CPU tùy theo máy của bạn.
# main.py
# Get Device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Chúng ta sẽ tạo một biến model bằng class SimpleModel đã tạo ở trước. Ở đây, mình cũng dùng hàm .to để chuyển model vào GPU nếu có.
# main.py
# Model
from models import SimpleModel
model = SimpleModel().to(device)
Loss Function và Optimizer
Chúng ta cần tạo loss function và optimizer để có thể train model. MNIST có 10 class nên đây là một bài toán phân lớp với nhiều class. Ngoài ra, model ở trên không sử dụng lớp Softmax ở cuối nên chúng ta sẽ dùng CrossEntropyLoss để PyTorch chủ động tính loss bằng Log Softmax và Negative Log Likelihood loss.
Bên cạnh đó, chúng ta sẽ dùng optimizer có sẵn trong package optim của PyTorch là optim.SGD với learning rate được định nghĩa ở đầu bài viết.
# Loss function
criterion = nn.CrossEntropyLoss()
# Optimizer
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
Training
Sau khi có đầy đủ data, model, loss function và optimizer. Chúng ta đã có thể tiến hành train model.
# main.py
num_steps = len(train_loader)
for epoch in range(num_epochs):
# ---------- TRAINING ----------
# set model to training
model.train()
total_loss = 0
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
# Zero gradients
optimizer.zero_grad()
# Forward
outputs = model(images)
# Compute Loss
loss = criterion(outputs, labels)
# Backward
loss.backward()
optimizer.step()
total_loss += loss.item()
# Print Log
if (i + 1) % 100 == 0:
print("Epoch {}/{} - Step: {}/{} - Loss: {:.4f}".format(
epoch, num_epochs, i, num_steps, total_loss / (i + 1)))
Ở đây, các bạn cần chú ý là phải gọi optimizer.zero_grad() trước khi gọi loss.backward() để xóa hết gradient của batch cũ trước khi tính gradient cho batch hiện tại. Bên cạnh đó, mình cũng gọi hàm to của images và labels để chuyển data vào GPU nếu có.
Validation
Bước validation cũng được thực hiện trong mỗi epoch để ta có thể biết được độ chính xác của từng epoch.
# ---------- VALIDATION ----------
# set model to evaluating
model.eval()
val_losses = 0
with torch.no_grad():
correct = 0
total = 0
for _, (images, labels) in enumerate(val_loader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
loss = criterion(outputs, labels)
val_losses += loss.item()
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Epoch {} - Accuracy: {} - Validation Loss : {:.4f}".format(
epoch,
correct / total,
val_losses / (len(val_loader))))
Tới đây, chúng ta đã có đầy đủ code để tiến hành training và validation. Các bạn có thể vào mục Source Code để lấy toàn bộ mã nguồn.
Tiến hành training và validation
Khi chạy toàn bộ đoạn code trên, chúng ta sẽ có kết quả như sau:
Epoch 1/20 - Step: 99/1875 - Loss: 0.7878
Epoch 1/20 - Step: 199/1875 - Loss: 0.5821
Epoch 1/20 - Step: 299/1875 - Loss: 0.4925
Epoch 1/20 - Step: 399/1875 - Loss: 0.4436
Epoch 1/20 - Step: 499/1875 - Loss: 0.4060
Epoch 1/20 - Step: 599/1875 - Loss: 0.3769
Epoch 1/20 - Step: 699/1875 - Loss: 0.3541
Epoch 1/20 - Step: 799/1875 - Loss: 0.3372
Epoch 1/20 - Step: 899/1875 - Loss: 0.3196
Epoch 1/20 - Step: 999/1875 - Loss: 0.3076
Epoch 1/20 - Step: 1099/1875 - Loss: 0.2957
Epoch 1/20 - Step: 1199/1875 - Loss: 0.2855
Epoch 1/20 - Step: 1299/1875 - Loss: 0.2782
Epoch 1/20 - Step: 1399/1875 - Loss: 0.2696
Epoch 1/20 - Step: 1499/1875 - Loss: 0.2611
Epoch 1/20 - Step: 1599/1875 - Loss: 0.2528
Epoch 1/20 - Step: 1699/1875 - Loss: 0.2457
Epoch 1/20 - Step: 1799/1875 - Loss: 0.2402
Epoch 1 - Accuracy: 0.9678 - Validation Loss : 0.1147
Epoch 1/20 - Step: 99/1875 - Loss: 0.1141
..............................
Epoch 20/20 - Step: 99/1875 - Loss: 0.0206
Epoch 20/20 - Step: 199/1875 - Loss: 0.0185
Epoch 20/20 - Step: 299/1875 - Loss: 0.0176
Epoch 20/20 - Step: 399/1875 - Loss: 0.0185
Epoch 20/20 - Step: 499/1875 - Loss: 0.0188
Epoch 20/20 - Step: 599/1875 - Loss: 0.0193
Epoch 20/20 - Step: 699/1875 - Loss: 0.0197
Epoch 20/20 - Step: 799/1875 - Loss: 0.0197
Epoch 20/20 - Step: 899/1875 - Loss: 0.0195
Epoch 20/20 - Step: 999/1875 - Loss: 0.0197
Epoch 20/20 - Step: 1099/1875 - Loss: 0.0196
Epoch 20/20 - Step: 1199/1875 - Loss: 0.0193
Epoch 20/20 - Step: 1299/1875 - Loss: 0.0196
Epoch 20/20 - Step: 1399/1875 - Loss: 0.0194
Epoch 20/20 - Step: 1499/1875 - Loss: 0.0198
Epoch 20/20 - Step: 1599/1875 - Loss: 0.0201
Epoch 20/20 - Step: 1699/1875 - Loss: 0.0201
Epoch 20/20 - Step: 1799/1875 - Loss: 0.0199
Epoch 20 - Accuracy: 0.9873 - Validation Loss : 0.0389
Các bạn có thể thấy rằng, ở epoch đầu tiên, chúng ta có độ chính xác trên tập validation là 96.78 %. Sau khi hoàn thành 20 epochs, chúng ta đã có được độ chính xác là 98.73 %.
Kết luận
Chúng ta đã hoàn thành được toàn bộ pipeline từ xây dựng data, tạo model và tiến hành huấn luyện mô hình CNN cho tập dữ liệu MNIST với độ chính xác là 98.73 %.
Các bạn có thể thấy rằng việc sử dụng PyTorch cho phép chúng ta tiếp cận sâu vào tất cả các thành phần của quá trình huấn luyện một cách đơn giản và vẫn đạt được hiệu suất tối ưu. Đối với framework deep learning khác như Keras, các bạn có thể làm rất đơn giản nhưng khi bạn cần can thiệp sâu vào thì khá khó. Còn đối với framework như Tensorflow thì theo mình thấy phức tạp hơn PyTorch rất nhiều.
Bài tiếp theo
Trong bài tiếp theo, mình sẽ viết về cách chọn mô hình để đạt kết quả tốt hơn bao gồm số channels, số lượng lớp, data augmentation …